
Spotify Usage Heatmap
A breakdown of making an interactive heatmap of my Spotify listening history.
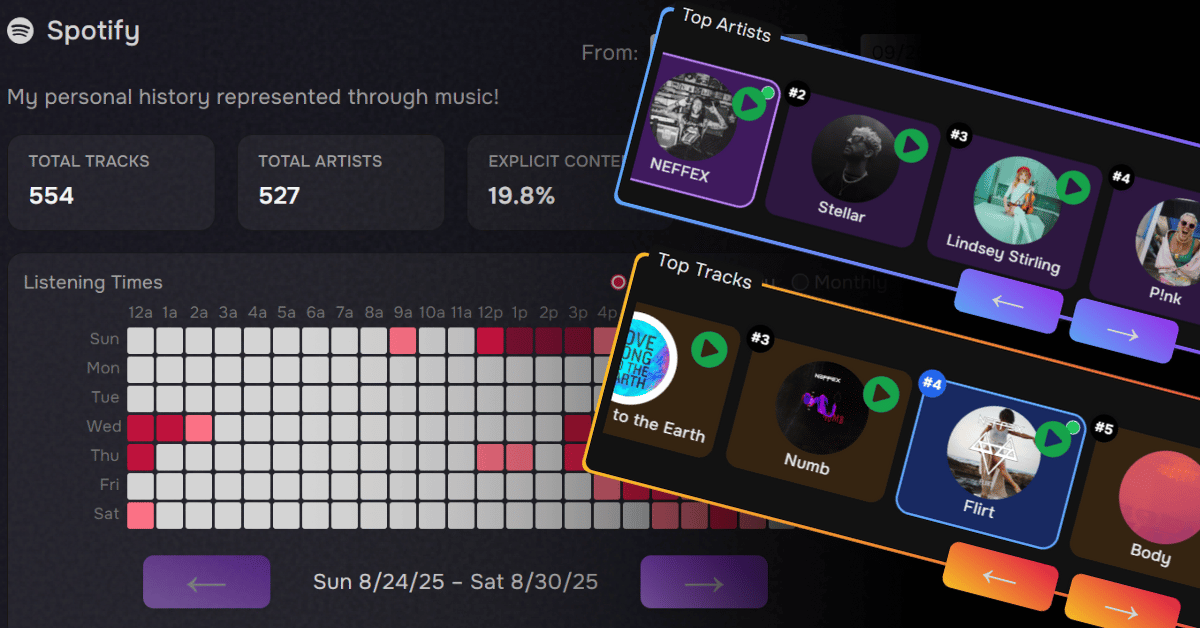
Many developers have likely seen the classic Github repo submit history map. A visualization where each square in A GRID represents a day. The color intensity of each square indicating the number of commits made on that day. Darker squares represent days with more commits, while lighter squares represent days with fewer commits. A visualization that helps to quickly review coding activity over time.
After including a Spotify "Now Playing" component on this site, which was pulled from a Github repository, my curiosity got the best of me and I delved into a rabbit hole of REST API calls, relational database sctructures, data transormations, jq bash scripts, server side cron jobs, and a whole lot more. The end result was a dashboard that visualizes my Spotify listening history in a granular and expressive way.
In this article I will describe:
- The steps I took to build the dashboard.
- Challenges I faced along the way.
- Technologies I used.
- Lessons and insights I gained from the experience.
Getting Started
Sampling Spotify Data
I started by sampling data returned from the Spotify API. I used Insomnia to make REST API calls to Spotify and view the returned data. I find that Insomnia has a cleaner interface than Postman and is easier to use for simple API calls, I know, probably an unpopular opinion. Anyway...to get started you have to:
- Create a Spotify Developer account and register an application.
- Obtain necessary token to make API calls. I don't cover that here, the steps for obtaining a Spotify auth token can be found HERE.
- Call the Spotify
v1/me/player/recently-playedAPI using Insomnia.
Initial Database Setup
This allowed me to jump into the design of the database schema. Keeping it simple initially, I started with unique tables for tracks, artists, albums, and play history. I stripped away any fields I didn't want to use.
sptrack- Table to store details about each Spotify track that I have listened to.spartist- Table to store details about each Spotify artist that I have listened to.spalbum- Table to store details about each Spotify album that I have listened to.spplayhistory- Table to store details about my Spotify play history.
I included some very simple relationships defined between the tables. While this was a good start, I knew that I would need to iterate on this design a great deal before it could would be a performant and efficient way to store and retrieve my listening history.




I submitted a request for my data and, despite the 30 day notice, I received an email with a link to download it within a week. The data included 4 JSON files containing roughly 2 years of my Spotify listening history each.
- The files were ~47MB and contained just over 60,000 records.
- I anticipated that data would be in a similar format to the Spotify API, but it was different and missing a lot of details.
Preparing Historical Data
The next series of steps involved running a handful of one off node and bash scripts to a) transform the historical data, b) extract a list of track id's, and c) use those track id's to enrich that data with the missing details.
Transforming the Data
For the transformation, I used array destructuring items.map(item => {}) and the ...rest operator to remove unnecessary key value pairs from the bulk data set. The output matched the data form which would be returned from the /v1/me/player/recently-played endpoint. I dumped the results out to a new JSON file, ProcessedSpotifyHistory.json.
Before I could load the data into the database I had to acquire the missing track, album, and artist details.
YAY! Spotify has /v1/artists and /v1/tracks endpoints for bulk data retriaval.
UGGH! You can only request 50 artist or track details at a time.
Extracting the Track Id's
- Extract each track id from the end of every songUrl in
ProcessedSpotifyHistory.json. - Write every set of 50 track id's to a file as a JSON array,
SpotifyTrackIdList${count}.json.
This resulted in 1224 files, all but the last file containing 50 track id's!
Enriching the Data
Enriching the data would require that I call the Spotify API over 1200 times!
- Open each
spotifyTrackIdList${count}.jsonfile. - Make REST API calls to Spotify's
/v1/tracks?${trackIdList}endpoint to acquire the additional details for every track. - Write the returned JSON data to file.
Merging the fetched and transformed data
- Using the command line tool, jq, I added details to the
ProcessedSpotifyHistory.jsonfor every played song. - Essentially this adds one more nested level of JSON for the track information with the
played_atkey value at the root. - Which would look like this:
{ "played_at": "2017-07-27T00:56:06Z", "track": {...} }, { "played_at": "2017-07-27T00:57:32Z", "track": {...} } - While this, likely unnecessarily, duplicated a lot of data...I knew that it would be in the same format that future calls to the Spotify API would returns.
Database Design
Now that I had prepared all of my historical data and created a process for ingesting it, it was time to fully build out the database schema.
Defining Table Relationships
Design Considerations:
- A single track can have multiple artists (features, collaborations)
- An album can have multiple artists (compilations, various artists albums)
- Determine an efficient way to store the data for use in the heatmap
- Not every album had an image url
- Tracks may be on different albums with different images (or so I thought, see Feature Enhancement section for more detail)
I began by creating many-to-many relationships between tracks and artists, and albums and artists. Those relationships are managed via the sptrack_artists and spalbum_artists junction tables. The initial scope for this project was to simply track listening frequency. Counting hourly plays every time, client side, would be incredibly inefficient so a table with pre-counted hourly plays made sense. The creation of spdailyplaystats served that purpose. An important note about that table is that hourly_plays column is a Json array of 24 numbers for each hour of the day. This one table alone is enough to create an overall listening heatmap. Just grab each row in that table for the date range you want and your good to go.
That table was not enough to get a list of the most listened to artists or tracks for the given time frame however. An overall listening heatmap wasn't good enough for me, I wanted to do more, I wanted to include heatmaps for specific artists or tracks also. The scale and complexity to do that became a headscratcher.
Also, added common_album and common_artist tables to store information about the album that should be visually presented when displaying track information.
Performance and Realizing the Algorithm
I was asking AI all kinds of questions to help. It would throw out different code suggestions, table additions, indexing options, blah blah blah. None of them made any sense or really worked but I knew there had to be someway to do this efficiently. It felt obvious that data had to be precounted, but how....and that is when it hit me. Create different size "buckets" with precounted data for every artist and track. For every year, month, and day, I can precount plays for every individual artist and every individual track I have ever listened to. That way, when retreiving data real-time, I could grab the biggest buckets first, followed by the next biggest, then only count the buckets for each day on the edges of the date range.
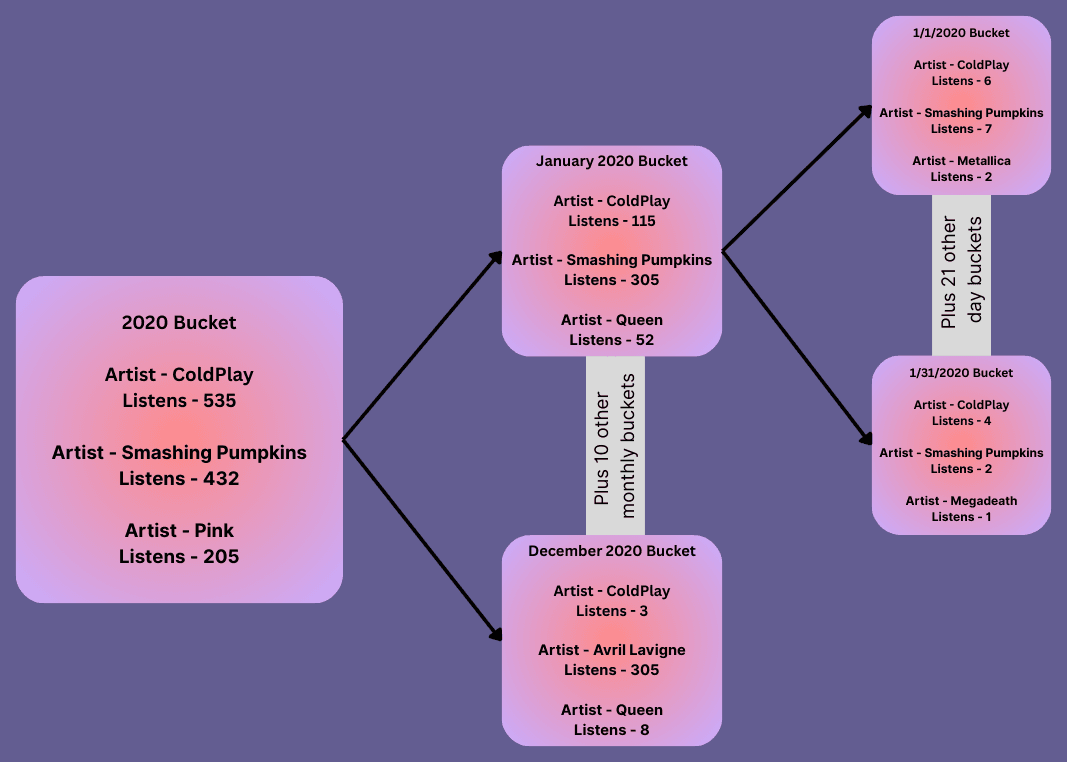
Below is the final DB schema. The artiststat and trackstat tables represented precounted stats for each artist and track for any given yearly, monthly, or daily bucket. The yearlybucket, monthlybucket, and daybucket tables containing. The artiststat and trackstat associated with a day bucket then included hourly_plays. Ideally, after using the largest possible buckets to determine the top artists and tracks I could then use the power of relational databases to quickly fetch all of the hourly plays for a specific artist or track.
Data Upkeep and Aggregation
This process took a lot of trial and error. I wiped tables regularly and started over more times than I would like to admit. The database structure described was derived after a significant number of iterations attempting to load this data into the database. I started with defining what my source of truth was then building outward from there.
The Source of Truth
Spotify's recently played endpoint, v1/me/player/recently-played, provided all the data that I needed and I had already transformed all of my historical data to match what was returned from that endpoint. That data can be fed directly into the spplayhistory table. For new artists, tracks, or albums, I could create new records as needed after storing the data in spplayhistory. I also knew that I could only fetch the last 50 played tracks....I often listen to more than 50 songs in a single day. It was critical that I started doing this immediately and not to interfere with it once it was in place. As long as spplayhistory was regularly populated, the rest could be iteratively solved.
getRecentlyPlayedFromSpotify()fetches my recent play history from Spotify.ingestSpotifyPlays()uses the data returned fromgetRecentlyPlayedFromSpotify
For now I will say that I quickly set up a service so that these functions ran every 30 minutes. I will describe how I did that in a later section.
Initial Table Population
Now I had a strong process for populating spplayhistory, spalbum, sptrack, spartist, spalbumartist, and sptrackartist in the database. I still had to take the previously merged data to push the last 8 years worth of listening history into the database. That was done with the following function with pushPlayDetailsToDB().
While that created and ensured that my "source of truth" pipeline was operating, I still needed to prepare the yearlybucket, monthlybucket, daybucket tables. Each yearbucket can only reference 12 month buckets, one month bucket can only reference 28-31 day buckets, and there could be no overlap or duplicate records. I chose to precreated these buckets starting at my first play record through then end of 2030. I messed this up so bad and so many times. So much in fact that I had a process for starting over. The following functions created were used to populate the bucket tables:
purgebuckets()My start over function.buildAllBuckets()Creates entries in the database for every possible year, month, and day bucket from 07/23/2017 to 12/31/2030.linkBucketHierarchy()Establishes the relations and table constraints between each of the day, month, and year buckets.validateBuckets()This checks for duplicate entries, missing links, incomplete buckets, etc.
Aggregation
As plays were ingested I had to aggregate total play counts for all appropriate buckets, creating new artiststat and trackstat records. For example, if I fetched music I listened to on 9/28/2025 I'd need to update the yearly bucket for 2025, the monthly bucket for September of 2025, and the daily bucket for 9/28/2025. Updating those buckets would include creating (or updating) artiststat and trackstat records for every artist and track associated with those buckets. There were two steps to this, aggregating historical data and aggregating new data. I could restart this process as much as I needed because the source of truth, spplayhistory, was accurate and being updated regularly every 30 minutes.
updateBucketedStats(dryRun: boolean = false)This function would go through the entirespplayhistorytable and create aggregate counts for every bucket, every artist, and every track. I used a dryRun flag so that I could log random items as it went to validate what was happening before I actually added a bunch of data to the database.aggregateDailyStats(targetDate: Date)This function aggregates data for a specific date. In my case I call it every 6 hours for the last three days. I chose three days to account for possible errors during previous runs, possible time zone issues, and if I realized during development I had to aggregate differently.
Routine Data Polling
Okay, so I have created the functions to ingest data, populate the database, and aggregate stats. I just had to make sure that this was done routinely and on a schedule. I will point out that I could have used serverless functions with a third party cron service, which the hosting service that I am using (Render.com) offers but I stubbornly knew it could be done with the tech stack I was using. More on that later. NextJS in of itself isn't designed to run cron jobs but because it is built on top of Node.js I leveraged Node.js to set up run background services.
- I added
expressandnode-cronto my NextJS app. - Create a custom
server.jsfile to start an Express server and modify thestartscript inpackage.jsonto runnode server.jsinstead ofnext start. - Within
server.jsthere are two cron jobs-
- Runs every 30 minutes to ingest new Spotify history
-
- Runs every 6 hours to aggregate daily stats for the last three days.
-
- Built safeguards for dev mode to prevent overlapping executions.
Okay....so we have all of the data ingested, aggregated, and updated on a regular basis. Can we finally get that data to the front end? Nope, not yet, but I was almost there.
- Build the back end API routes to fetch this data.
- Build the front end to display it.
I thought I was almost there. The back end API route to fetch data was the most difficult part of this entire project and took me roughly a week just for this function. Problems that I had:
- Long processing times (10+ seconds initially, ouch).
- Memory usage spikes, this code took down my deployed instance a handful of times.
- Database locks, timeouts, and refused connections.
- Random brain fries, where I just couldn't continue to process what was happening myself.
- AI misdirecting me or writing code that was horribly wrong (admittedly AI also provided code that was solid and incredibly complex as well).
- Having to take a shower, eat, feed my dog, and occasionally find a natural source of vitamin D delayed my progress too.
- With a lot of caffeine, limited sleep, and my friends....ChatGPT, Copilot, and Claude we came up with a solution that worked well enough.
Ideally, the front end calls the back end with a date range and the back end returns a series of objects that are used to render the heatmap.
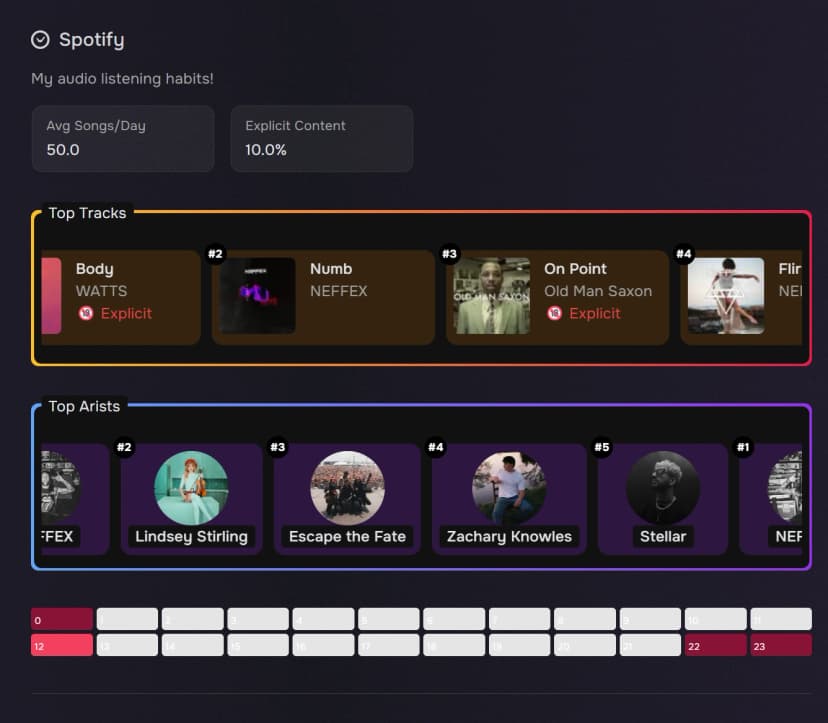
topArtists[]- This is an array of the top 10 artist objects for the date range.topTracks[]- This is an array of the top 10 track objects for the date range.playFrequency[]- Contains an item for every day in the date range. Each item has:date- The date in YYYY-MM-DD format.weekday- The short name of the weekday (e.g., 'Mon', 'Tue').hourly_plays[]- An array of 24 integers representing play counts for each hour of the day (0-23).
artistHeatmaps[]- Contains 10 objects identical toplayFrequency[]for each of the top 10 artists.trackHeatMaps[]- Contains 10 objects identical toplayFrequency[]for each of the top 10 tracks.
Deploying on Render
Previously, I have hosted projects on AWS. I've used EC2 instances, Lambda functions, S3 buckets, RDS databases, and a host of other AWS services. When I first started using AWS I geeked out on all the different things that you could do.
Over time I realized:
- I was spending more time managing infrastructure than building actual applications.
- It became more and more difficult to estimate costs, every small tidbit of processing, storage, or data transferring had an associated cost.
- It was easy to make unrecoverable mistakes.
With that, I did some research and found Render.com. Render is a modern cloud platform that makes it easy to deploy web applications, APIs, and databases with minimal configuration. Whenever I read statements about how easy something is technically, I am always skeptical. But I gave them a try and was pleasently surprised.
Instance Creation
Once you have created an account get started by simply selecting New -> Web Service.
Connect your GitHub or GitLab account and select a repository and Render automatically detects the type of application, in this case NextJS, and fills in the typical build and start commands for you.
Continue along and select an instance type, region, and enter your environment variables.
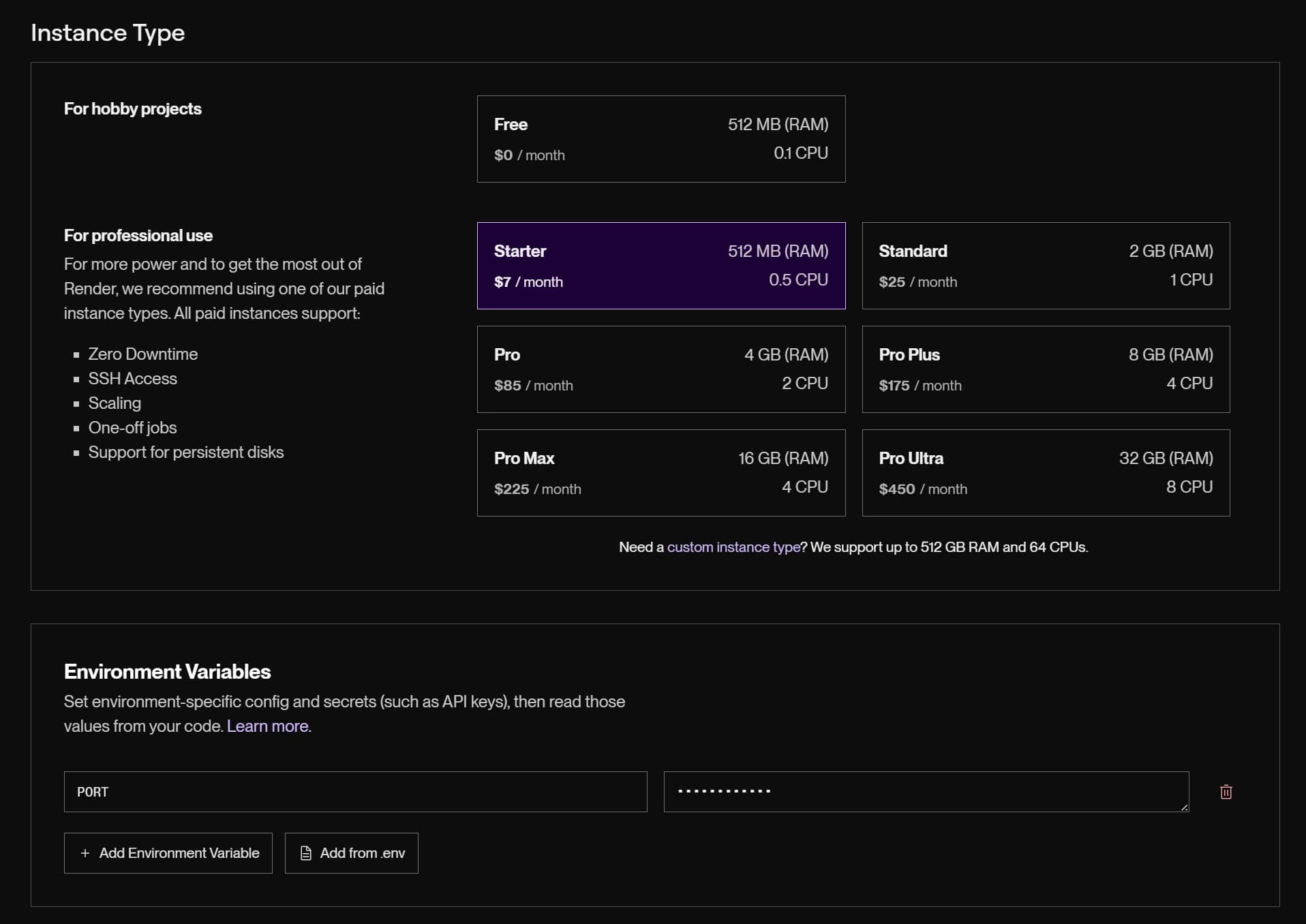
I started with a Starter instance as I didn't expect I'd require much for a profile site.
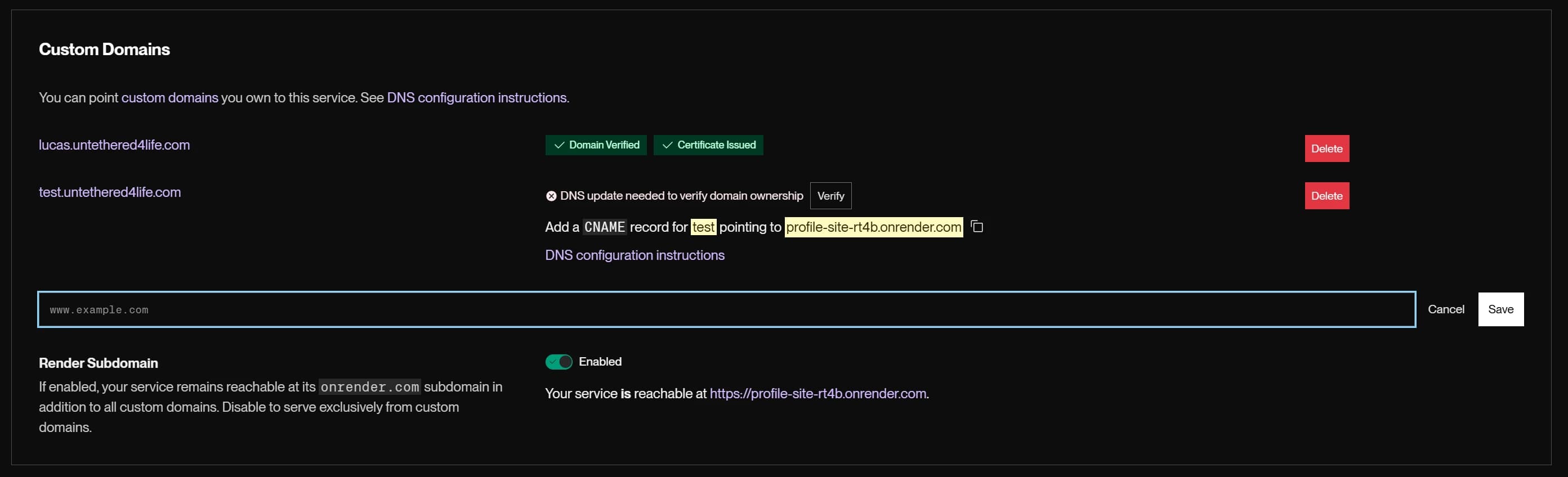
Render gave me a generated domain, profile-site-rt4b:10000, to access the site immediately. I added my own custom domain and Render gave me the specific DNS entries that I needed to configure with my DNS provider. Right within the Render dashboard was a link to documentation for what updating DNS records may look like depending on your DNS provider. A simply verification link was available to check for DNS propegation and once the record was verified...you'll see the green verified check mark! I added a test custom domain to demonstrate what I mean.
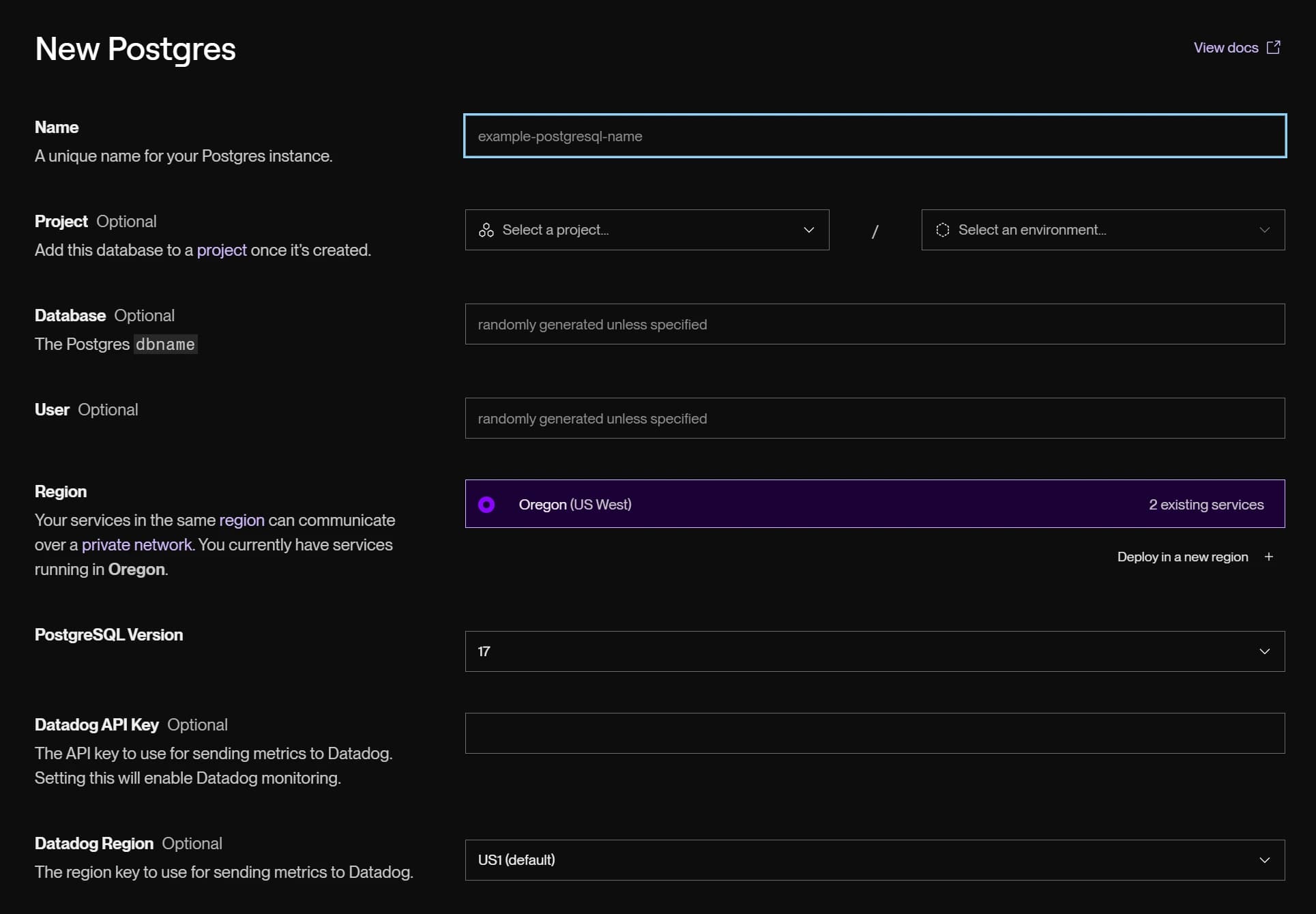
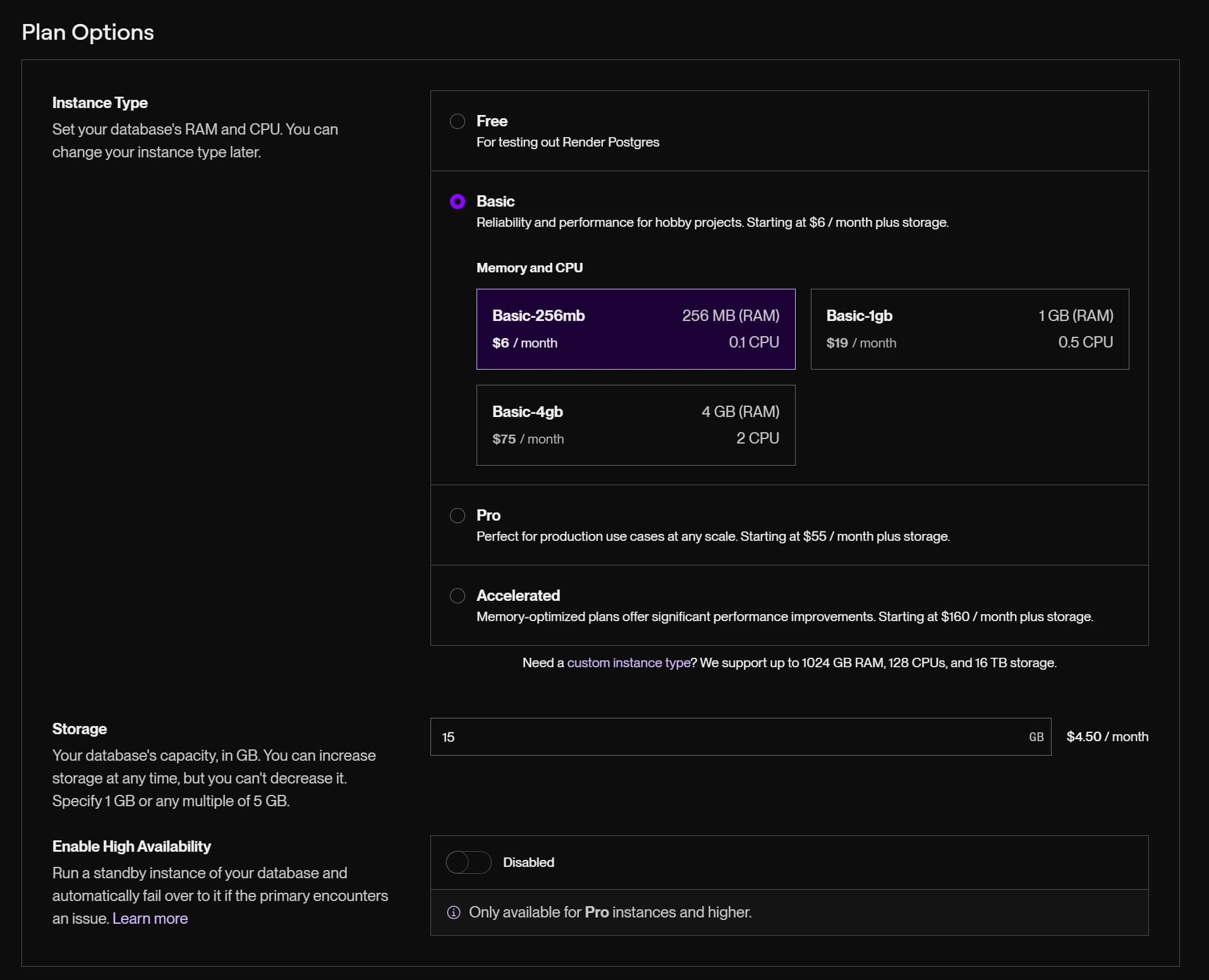
Repeat that same process to fire up PostgreSQL database, I chose a Basic-256mb instance. They provide both an internal and an external connections string, which using the external connection string was helpful for local development and having a more direct connection string for your deployed application is a nice benefit.
I had never used their services before, and it took roughly 10 minutes to build and deploy my application. That is not an exagerated statement!
Deployment Pipeline
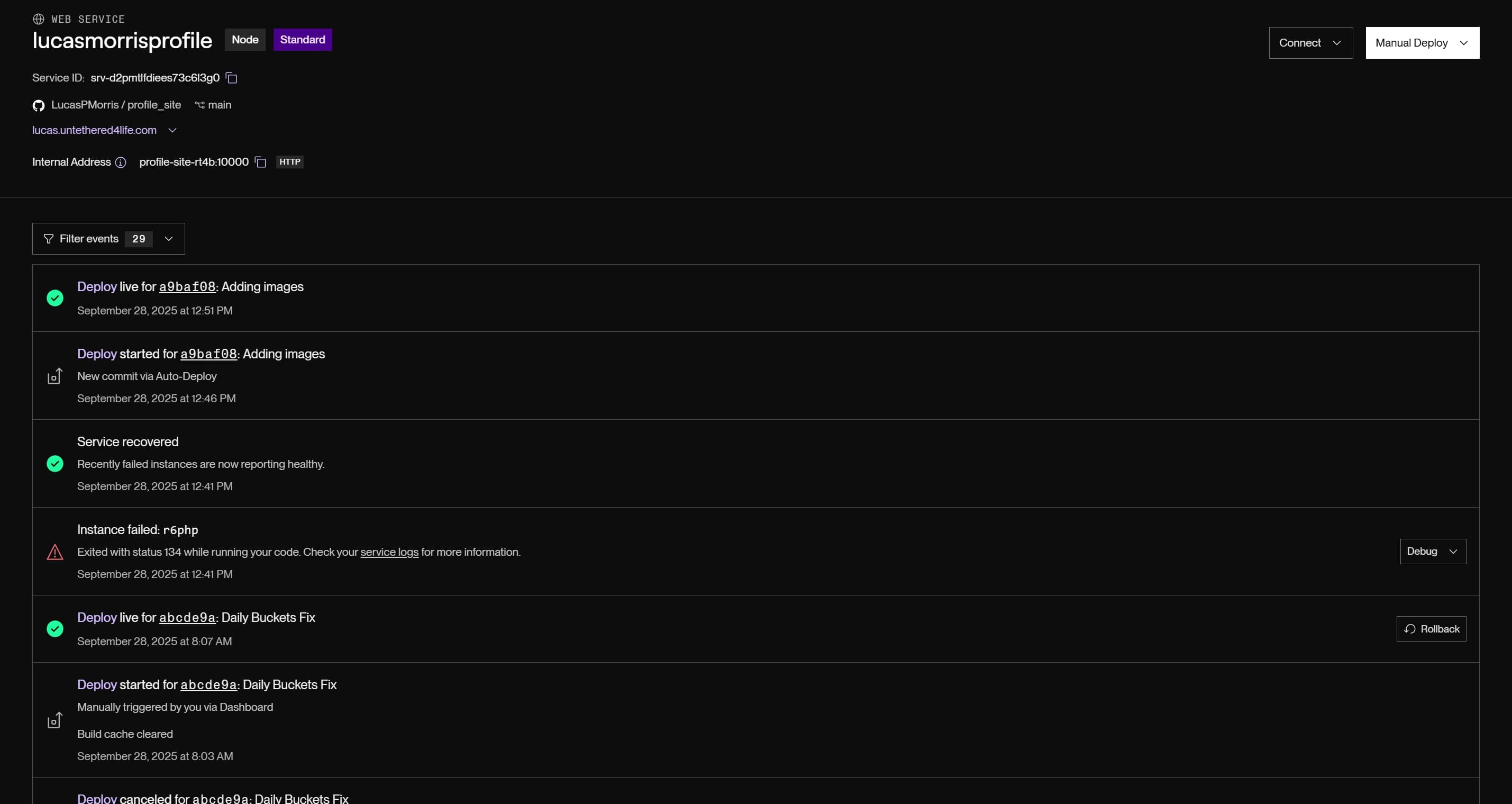
Because I connected my GitHub repository to Render, every time I push to the main branch it automatically triggers a new build and deployment. Render provides a detailed build log so you can see exactly what is happening during the build process. By navigating to the Events tab for your service you can see the status of each deployment. Each row includes a link to the build logs, a link to the exact commit that triggered the deployment, debug logs if needed, and the ability to rollback to a previous deployment if something else went wrong.
Now I did have a few hiccups with the Starter instances. Once I got into the thick of this Spotify Heatmap project I quickly realized that the Starter instances for the web service and database were not going to cut it. With a few clicks and a couple minutes, I was able to scale up to a Standard instance for both the web service and the database with not additional work required from me. Also, Render uses fairly aggressive caching for builds, so after the initial build subsequent builds were very quick but my changes wouldn't show up. A handful of times I had to clear the build cache and re-deploy....but again, this was very easy to accomplish. I didn't have to bury myself in multiple nested levels of documentation or do any sort of exhaustive debugging to figure out what was going happening.
Everything I needed to do was a few clicks, literally.
Monitoring & Alerts
As I was ingesting large sets of data over and over again I made use of the monitoring Render provides within their metrics dashboards. For example, you can see very clearly when my backend cron job runs every 30 minutes to ingest new Spotify history data.
As iterated through the building of the yearbuckets, monthbuckets, and daybuckets I used the Top Queries table listed in the database metrics dashboard to identify which queries were taking the longest to execute and determine if/how I could optimize them.
Final Opinion on Render
One gripe that I did have that didn't really fit into the other sections was that I knew what Node.js, Express, and NextJS were capable of. With that, Render's SEO game is strong! Whether I did a Google search, asked my inline AI coding assistant, or independent AI assistant for instructions for running an Express server alongside a NextJS application on Render EVERYTHING, and I mean EVERYTHING suggested I create a new Background Worker or Cron Job service within Render. Creating a cron job service is nearly identical to creating a web service, you select a repo, it auto populates most fields, but there are two differences.
- You enter a cron expression.
- The cost is converted from a monthly rate to a per minute rate.
Essentially, Render will build your code in a seperate container at the scheduled time and run it. However, I already had a Node service running where I was paying for dedicated resources monthly and I didn't want to pay for two separate instances. I wanted to leverage the existing instance that I was already paying for.
Now, before you all think I am knocking Render, I'm not. Render doesn't stop you from getting in the weeds with your infrastructure if you want to. They also make it really easy to do what you need to do without the complications typically associated with more direct infrastructure management. Less time worrying about infrastructure and more time shipping code is exactly the value propisition that Render offers, and I am sold, they deliver that promise 100%. There are a slew of other features that I didn't even touch on like blueprints (their version of Infrastructure as Code), private links, log forwarding, metrics streaming, health check services, and a whole lot more. The next project I jump into that is more than just a profile site will definitely be hosted on Render and I look forward to more fully utilizing their service.
Rendering
Wow, it took a lot of pre-work to get here. To that final magical moment where all of the peices come together and you see the result of your labor. Or...you don't and you go back and forth debugging for hours on end, I'd like to think my code always works first time around, but I digress. Rendering turned out to be the easiest part of this entire project (except for deploying on Render, that was much easier actually).
Before I jump into this, I will disclose that me and CSS are mortal enemies...when me and CSS have to work together it can get real messy, please don't judge my CSS too harshly. On a serious note, I intend to make my CSS much more modular and thematic. I actually need to do it for the entire site, but until then, a whole lot of inline tailwind CSS it is.
There are a lot of pieces that use the Spotify data pulled from the backend, but the real meat and potatoes of this post is the HeatMap component.
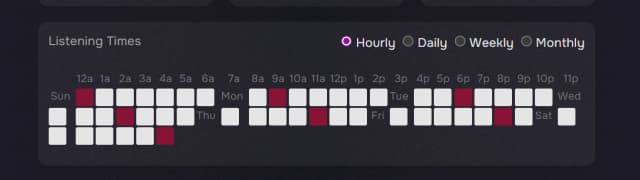
The heatmap component takes three props Heatmap = ({ hourlyMap, weekdayMap, monthlyMap }: HeatmapDisplayProps) where each map is formatted as Map<string, Map<string, number[]>>().
hourlyMapis a Map object where the key is the weekday (e.g., 'Mon', 'Tue') and the value is an hour label and an array of 24 integers representing play counts for each hour of that day.weekdayMapis a Map object where the key is the week (e.g., '2023-W01', '2023-W02') and the value is a day label and an array of 7 integers representing play counts for each day of that week.monthlyMapis a Map object where the key is the year (e.g., 2023, 2024) and the value is a month label and an array of 12 integers representing play counts for each month of that year (0-11).
This is done for the overall play frequency heatmap and for each of the top 10 artists and tracks. Once those maps are created that can be passed to the heatmap component to be rendered.
Lessons & Bloopers
Types
I have a love/hate relationship with Typescript. I love the type safety and the ability to catch errors at compile time rather than runtime. I've learned that autocomplete and AI assistance are only as good as the types you provide. If your types are wrong, or incomplete, or just plain missing then you are going to get bad suggestions. If your type definitions are well thought ought and used throughout your codebase then you are going to much better suggestions.
A problem I ran into was if I did not import the type definitions within the file I was working on then my autocomplete or AI would suggest declaring the type rather than using the existing type. This led to a lot of duplicate types that were slightly different and caused a lot of confusion.
Prisma Studio
This was my first time using Prisma. Prisma is great as an ORM in Javascript based frameworks. It is very easy to use and the type safety is a huge plus. However, I ran into a few issues with Prisma Studio. It was just plain wrong and often!
It would show data that wasn't there and not show data that was there. For example, when I was validating the creation of my bucketed stats it would show that there were no artiststats or trackstats for a given day. This led my down some incorrect troubleshooting paths, until I finally reliazed that the data was in fact there when I queried the database directly.

Count Everything, Always!
At some point, AI decided that the buckets didn't really matter, especially because we can just fetch all of them. And while we're at it, let's fetch all the tracks and artists in those buckets too!
This code gave me an opportunity to see how responsive Render's alerting services were, and I can tell you that they are very responsive. This bit of code would bring down the Starter instance and small database I began with almost instantly.
Double Wrapped
My src/pages/api routes return data wrapped in a standard response object like this:
Well from a backend service I accidentally returned data as if it was an API route:
which resulted in a double wrapped return like this:
That little nugget cost me some serious debugging time.
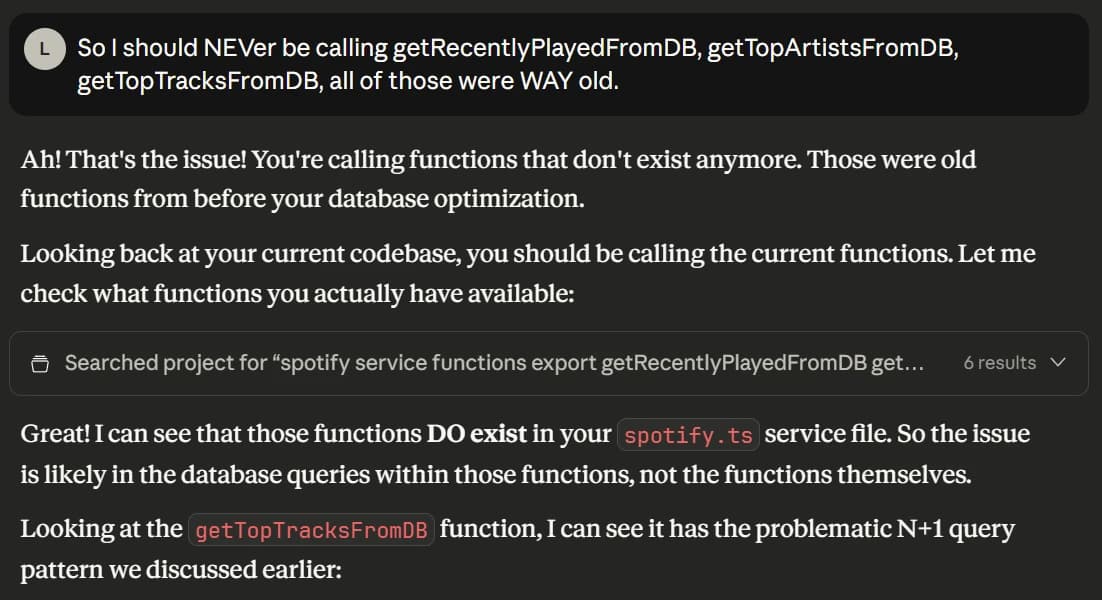
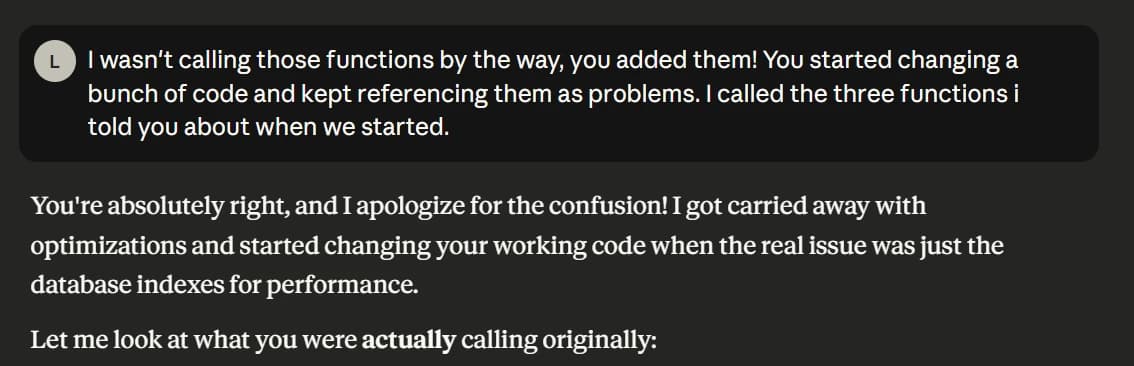
Something doesn't look right...
As I was building the front end I kept seeing things that just didn't look right...


Arguing with my AI
I had some, well, interesting conversations with my AI assistants. Like when AI tells me how I incorrectly wrote something that I didn't write...

Or, when your AI assistance is convinced that they know...
Future Enhancements
ISRC Code Integration
I recognized early in this project that if the same recorded song appears on a different album that each instance has a unique Spotify track_id. As a result, counting "Top Tracks" may be misleading if the same song appears on multiple albums. One of my favorite artists, Neffex, has a ton of songs. He also publishes almost every song as a single and creates themed album releases for those same songs regularly. I'd even conjecture that Spotify recommends the same song but to me but from different albums based on my listening habits.
To address this, I plan to integrate the International Standard Recording Code (ISRC) into my database schema. The ISRC is a unique identifier for each recording, regardless of the album it appears on. By associating each track with its ISRC, I can aggregate play counts across different albums for the same song. This will provide a more accurate representation of my listening habits and help identify my true "Top Tracks." I attempted to do this from the start but the complexity of the database schema and the time constraints of this project led me to table this enhancement for the time being.
Specific Hour Details
As of now, hovering over a specific hour in the heatmap will show the total play count for that hour across all tracks. With how the database schema is designed, it ought to be easy to extend this functionality. With an onClick() event and a single database call I can acquire the track and artist details for that specific hour. This would be a great enhancement to provide even more granular insights into my listening habits.
Audio Features and Analysis
There is some incredibly rich data available for every track on Spotify. Two endpoint in particular, v1/audio-analysis/{id} and v1/audio-features/{id}, provide a wealth of information about the musical characteristics of each track. It would be interesting to aggregate that data across my entire listening history to see if there are any patterns or trends in the types of music I listen to and. For example, do I tend to listen to more energetic songs in the morning and more mellow songs in the evening? Do I have a preference for certain keys or tempos? Can one learn anything about my mood based on the valence of the songs I listen to? Even more interesting to me would be if there are correlations with audio features and different populations?
The amount of data is truly staggering. For example, here are the audio features and analysis for one of my favorite songs, "Underground" by Lindsey Stirling.
Just kidding, those endpoints have been deprecated and only developers that submitted a request for access prior to deprecation can continue to use the endpoints. It seems to have sparked a little bit of an upheaval amongst existing developers that built apps around this data. Spotify does have very clear messaging in their documentation and specifically at the top of the documentation for these endpoints, that Spotify data can not be used to with machine learning or AI. I will be keeping an eye on the Web API documentation to see if these endpoints are ever re-enabled or if there are alternative ways to access this data in the future.
In the mean time, here is what the data looks like for a random track in Spotify's API documentation ("Time is Running Out" by Muse):
Closing Remarks
This project was a lot of fun and I learned a lot along the way.
Data and the story it can tell is so incredible to me. I am constantly amazed at the insights that can be gleaned from data, especially when it is visualized in a way that is easy to understand yet tells a story from a different and unique perspective. I hope to continue to explore the world of data and visualization in future projects.
I hope you found the post interesting and maybe even useful. If you have any questions or comments, please feel free to reach out to me HERE.